Today the Boltz team announced the biggest expansion of the Boltz family so far: two new design pipelines, BoltzMol-1 and BoltzProt-1, plus a new Boltz API for running their models in production. We're glad to share that all three are available on Tamarind Bio from launch day, alongside the 300+ tools scientists already run on our platform.
Here's what's new, what the Boltz team reports about it, and why we think Tamarind is a useful place to put these models to work.
BoltzMol-1: a hit discovery pipeline for small molecules
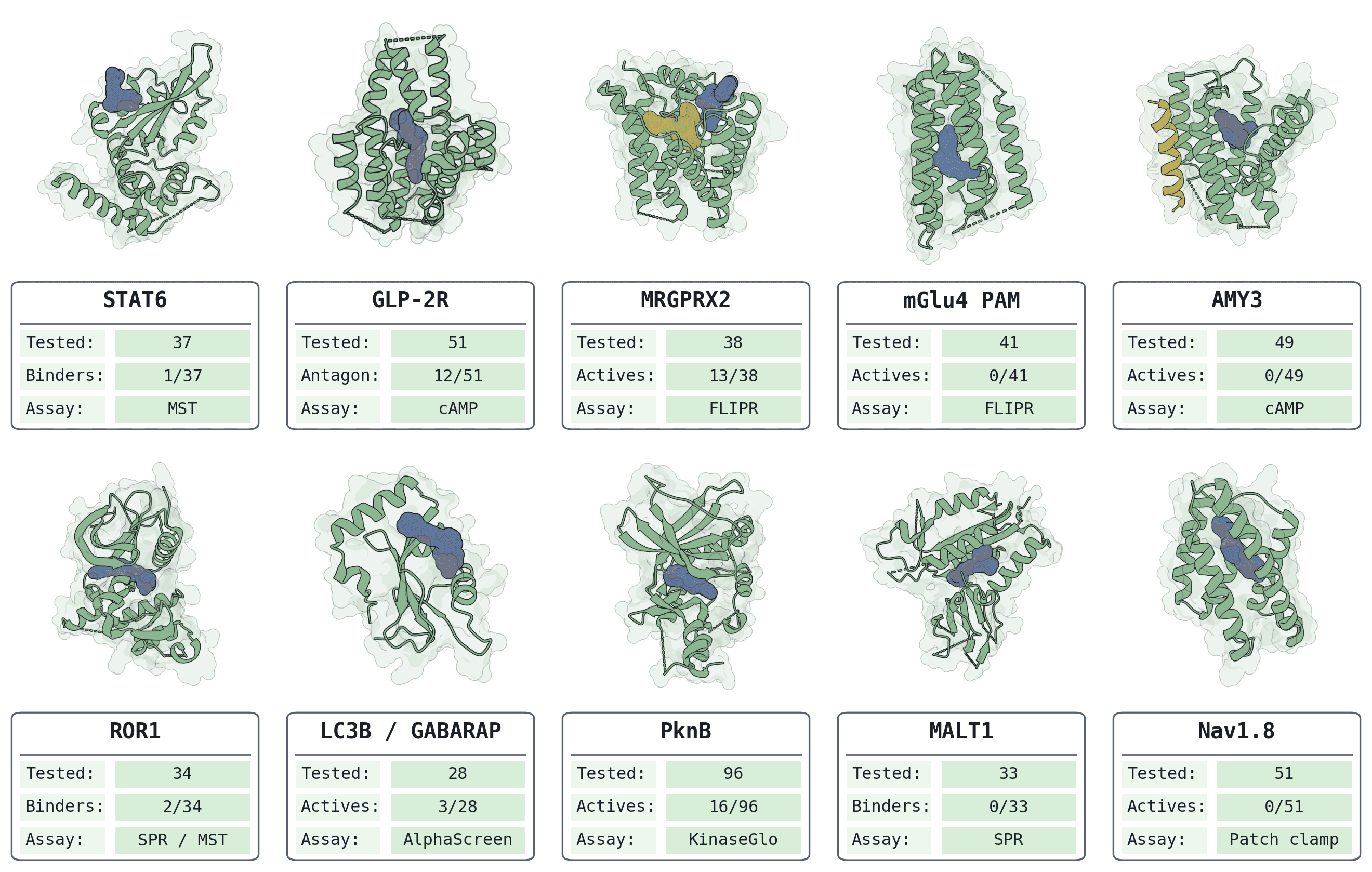
BoltzMol-1 is described by the Boltz team as the first generative hit-finding pipeline in the Boltz family. It builds on the affinity prediction first shown in Boltz-2, and it runs in two modes. The first ranks compounds that are already buyable from in-stock catalogs. The second generates and searches a make-on-demand chemical space that the authors put at more than 74 billion compounds. In both modes, the pipeline filters designs through ADME models for properties like solubility and permeability, which the team says happens at no additional compute cost.
On results, we'd point readers to the Boltz technical report rather than treating any single number as settled. The authors report validated hits on 6 of 10 targets while testing only 28 to 51 compounds per target, including work against the pseudokinase ROR1, the GPCRs MRGPRX2 and GLP-2R, and the TB kinase PknB. They describe these as micromolar starting points for medicinal chemistry rather than finished leads, and they note that some targets did not produce confirmed hits under the budget tested. We think that framing is the right one: this is an early-stage hit discovery tool, and the most credible read on its performance is the authors' own writeup and your own runs on your own targets.
BoltzProt-1: binding-aware protein design
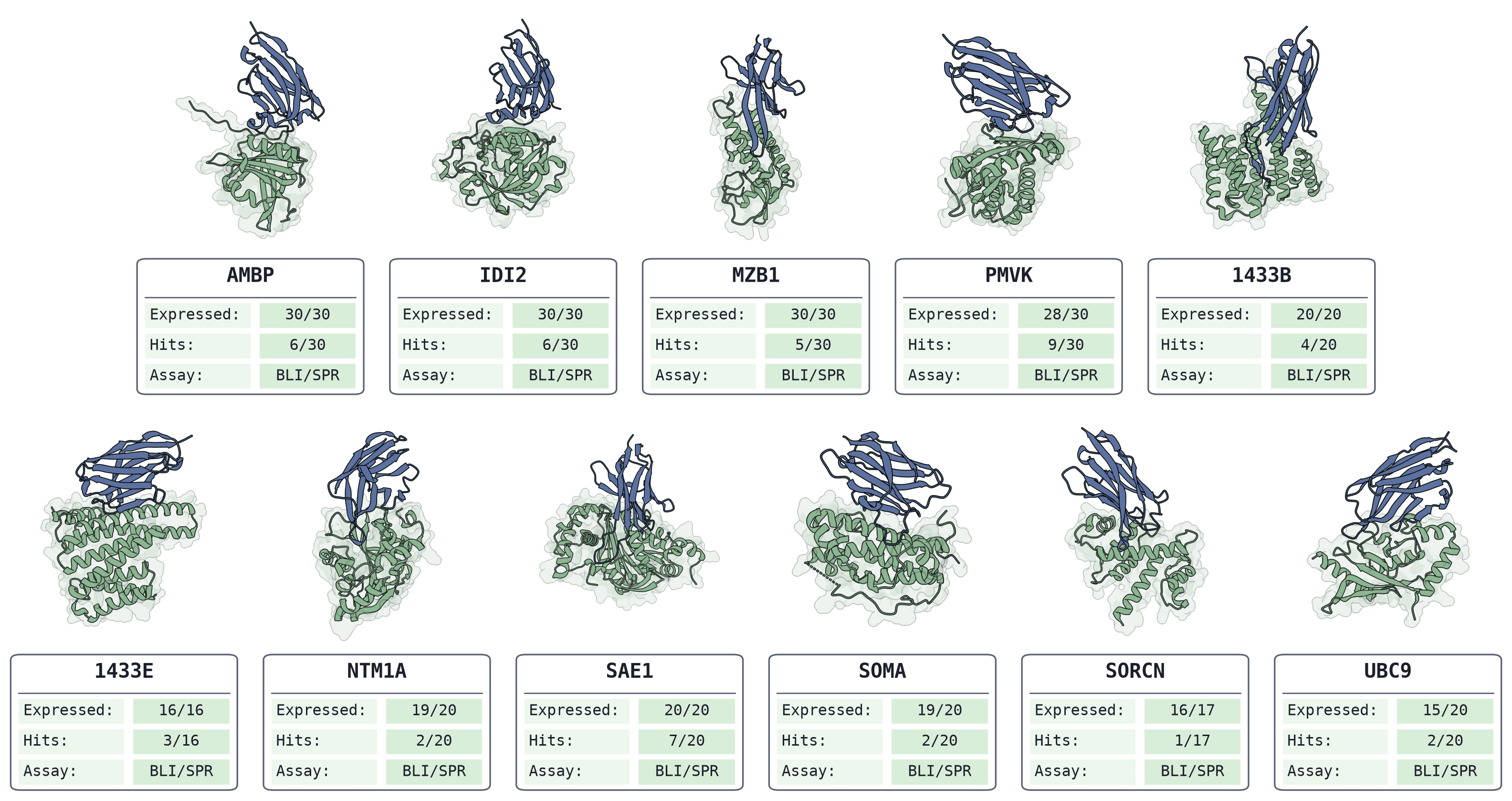
BoltzProt-1 is positioned as a substantial advance over BoltzGen for protein design. The headline addition is Boltz-PPI, a protein-protein interaction model that the team trained to score proposed interactions directly, rather than relying mainly on structural confidence when ranking candidate binders. The argument the authors make is that structural confidence answers a proxy question (is the predicted complex geometrically plausible?), while a dedicated interaction model gets closer to the experimental question of whether two proteins actually bind.
In a zero-shot nanobody design benchmark across ten novelty-controlled targets, the Boltz team claims BoltzProt-1 nearly tripled the hit rate relative to BoltzGen and doubled the number of targets with a validated binder, without changing the generative model or testing additional designs. In other words, the reported gain comes from better prioritization of the same candidate pool. The authors also report that the selected binders pass a stringent developability panel and compare favorably to clinical-stage therapeutic nanobodies. As with BoltzMol-1, these are zero-shot results on deliberately hard targets, with no affinity maturation, so the team is careful to note that downstream optimization is still required. We'd treat the benchmark numbers as the authors' claims pending independent and in-house validation.
The Boltz API: frontier models, built for agents
This agent-first design lines up closely with where we see computational discovery heading: systems that propose a binder, fold it, score its affinity, and decide what to try next, looping thousands of times without a human in the inner loop.
Why run the Boltz models on Tamarind
A new pipeline is most valuable when it isn't running in isolation, and that's the gap Tamarind is built to fill. On Tamarind you can compose BoltzMol-1 and BoltzProt-1 into larger workflows alongside hundreds of open-source tools, other proprietary models, and your own code, all on one neutral infrastructure layer and through the same web, API, and agent interfaces you already use.
In practice that means you can generate candidates with one model, refold with another, score with a third, and apply your in-house developability or selection filters, without stitching together separate services or moving data between vendors. You can also benchmark the new Boltz pipelines head to head against the open-source tools and alternative models you already trust, on your own targets, which is the only evaluation that ultimately matters. That composability, across open and proprietary models on a single platform, is something no individual model API provides on its own.
Getting started
BoltzMol-1, BoltzProt-1, and the Boltz API are available on Tamarind today, through the web app, our API, and our MCP server for agentic workflows. If you're already a Tamarind user, the new pipelines show up in the same interface you use for everything else. If you're not, you can spin up a run in minutes.
Congratulations to Gabriele Corso, Jeremy Wohlwend, Saro Passaro, Hannes Stärk, Charlie Harris, Talip Uçar, and the rest of the Boltz team on the release. We're looking forward to seeing what scientists build with these models, and to reporting back on what we learn running them at scale.